MMLongBench-Doc: Benchmarking Long-context Document Understanding with Visualizations
Abstract
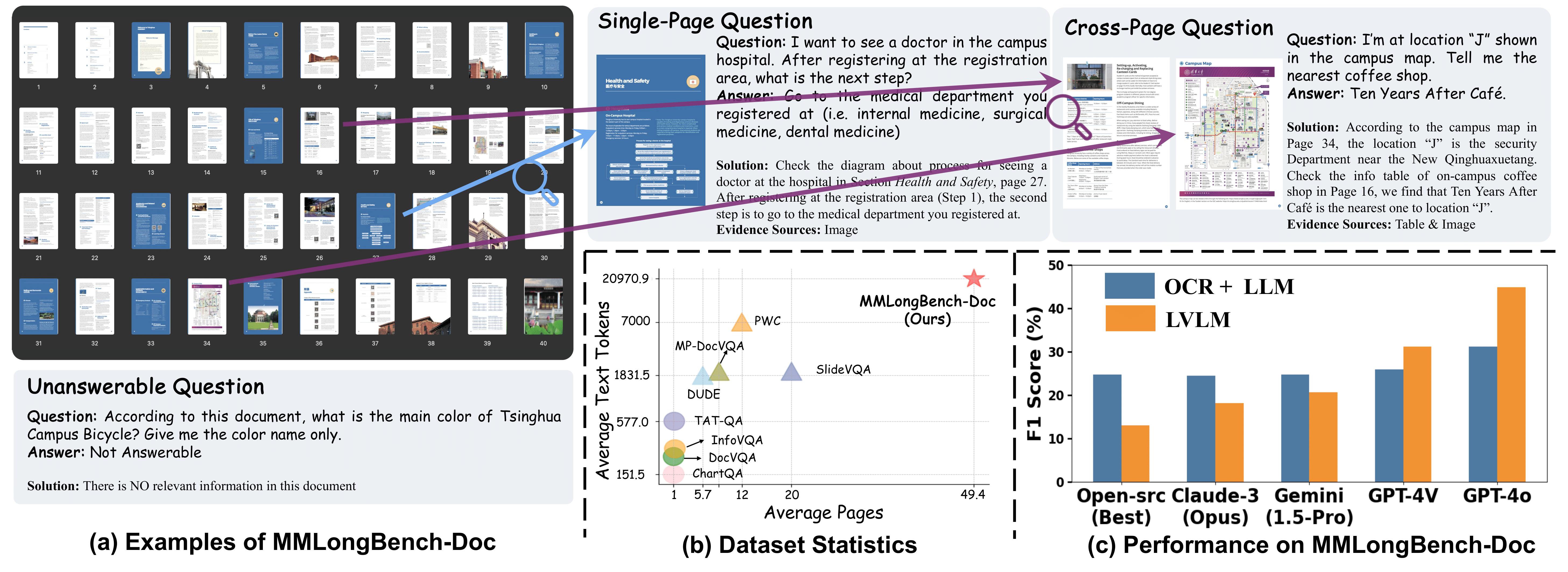
Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU). However, their abilities on long-context DU remain an open problem. This work presents MMLongBench-Doc, a long-context, multi-modal benchmark comprising 1,091 expert-annotated questions. Distinct from previous datasets, it is constructed upon 135 lengthy PDF-formatted documents with an average of 47.5 pages and 21,214 textual tokens. Towards comprehensive evaluation, answers to these questions rely on pieces of evidence from (1) different sources (text, image, chart, table, and layout structure) and (2) various locations (i.e., page number). Moreover, 33.0% of the questions are cross-page questions requiring evidence across multiple pages. 22.5% of the questions are designed to be unanswerable for detecting potential hallucinations. Experiments on 14 LVLMs demonstrate that long-context DU greatly challenges current models. Notably, the best-performing model, GPT-4o, achieves an F1 score of only 44.9%, while the second-best, GPT-4V, scores 30.5%. Furthermore, 12 LVLMs (all except GPT-4o and GPT-4V) even present worse performance than their LLM counterparts which are fed with lossy-parsed OCR documents. These results validate the necessity of future research toward more capable long-context LVLMs.
🔥Highlight
- Multi-modality: All selected documents are PDF-formatted with rich layouts and multi-modal components including text, table, chart and image. We annotate questions carefully from these multi-modal evidences.
- Long-context: Each document has an average of 47.5 pages and 21,214 tokens. Additionally, 33.0% of the questions are cross-page questions which necessitate the information collection and reasoning over multiple pages.
- Challenging: Experiments on 14 LVLMs demonstrate that long-context document understanding greatly challenges current models. Even the best-performing LVLM, GPT-4o, achieves an overall F1 score of only 44.9%.
MMLongBench-Doc Overview
The automatic understanding of lengthy documents (Long-context Document Understanding; DU) stands as a long-standing task in urgent and practical needs. Although many LVLMs now claim (and show promising cases) their capabilities on long-context DU, there lacks a unified and quantitative evaluation of existing models due to the absence of related benchmark.
To bridge this gap, we construct MMLongBench-Doc which comprises 135 documents and 1091 qustions (each accompanied by a short, deterministic reference answer and detailed meta information.). The documents have an average of 47.5 pages and 21,214 tokens, cover 7 diverse domains, and are PDF-formatted with rich layouts and multi-modal components. The questions are either curated from existing datasets or newly-annotated by expert-level annotators. Towards a comprehensive evaluation, the questions cover different sources like text, table, chart, image, etc., and different locations (page index) of the documents. Notably, 33.0% questions are cross-page questions necessitating comprehension and reasoning on evidences across multiple pages. And 22.5% questions are designed to be unanswerable for reducing the shortcuts in this benchmark and detecting LVLMs' hallucinations.
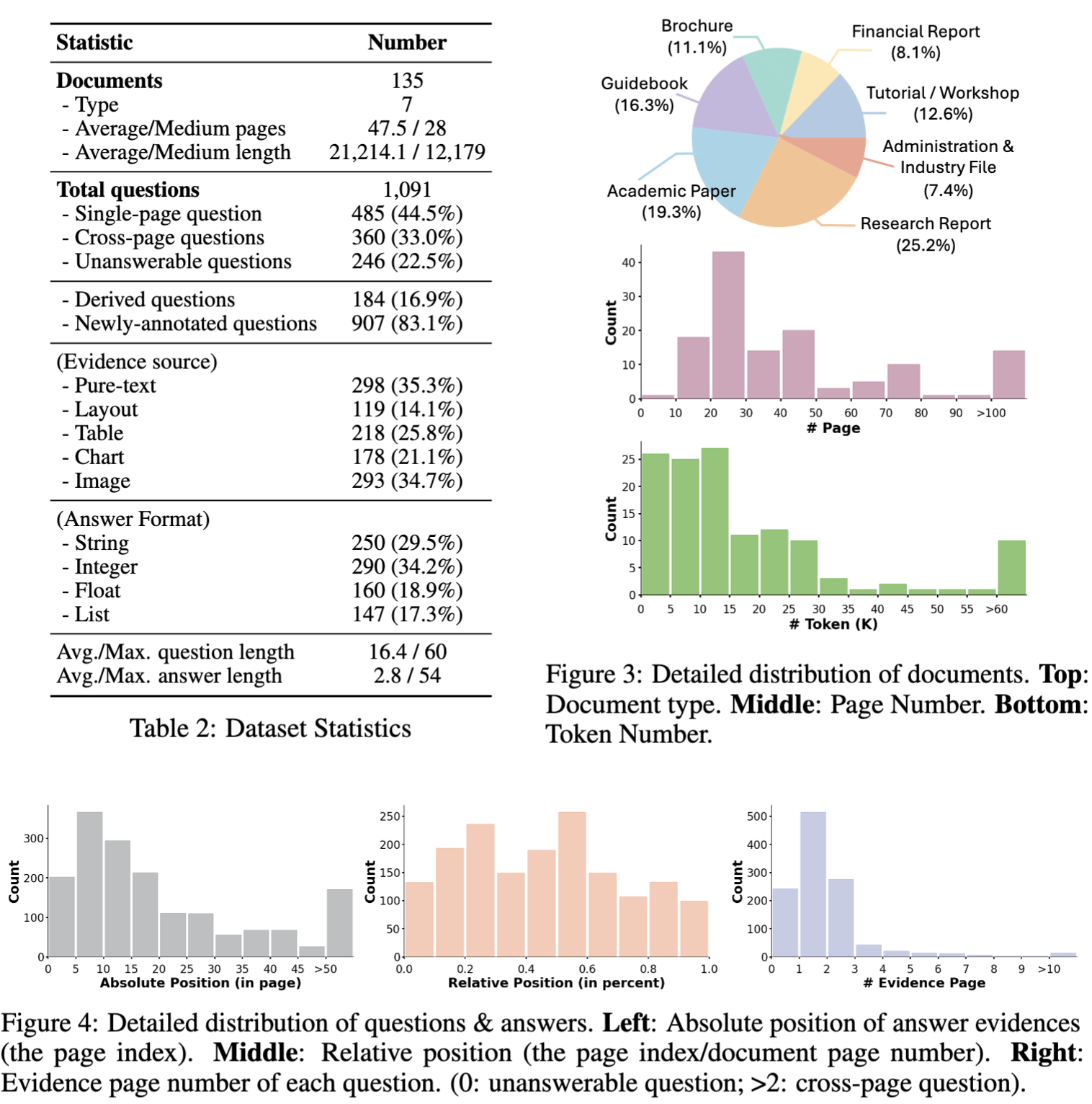
MMLongBench-Doc Construction
The annotation pipeline of MMLongBench-Doc includes three stages. (1) Document Collection: We firstly curate documents from both existing datasets and new resources. (2) Q&A Collection: We manually edit existing questions (evaluate and revise/remove them if necessary) and/or create new questions. Answers and other meta-information are also annotated in this stage. (3) Quality Control: We further adopt a semi-automatic, three-step quality control to revise/remove these unqualified questions and correct problematic answers.
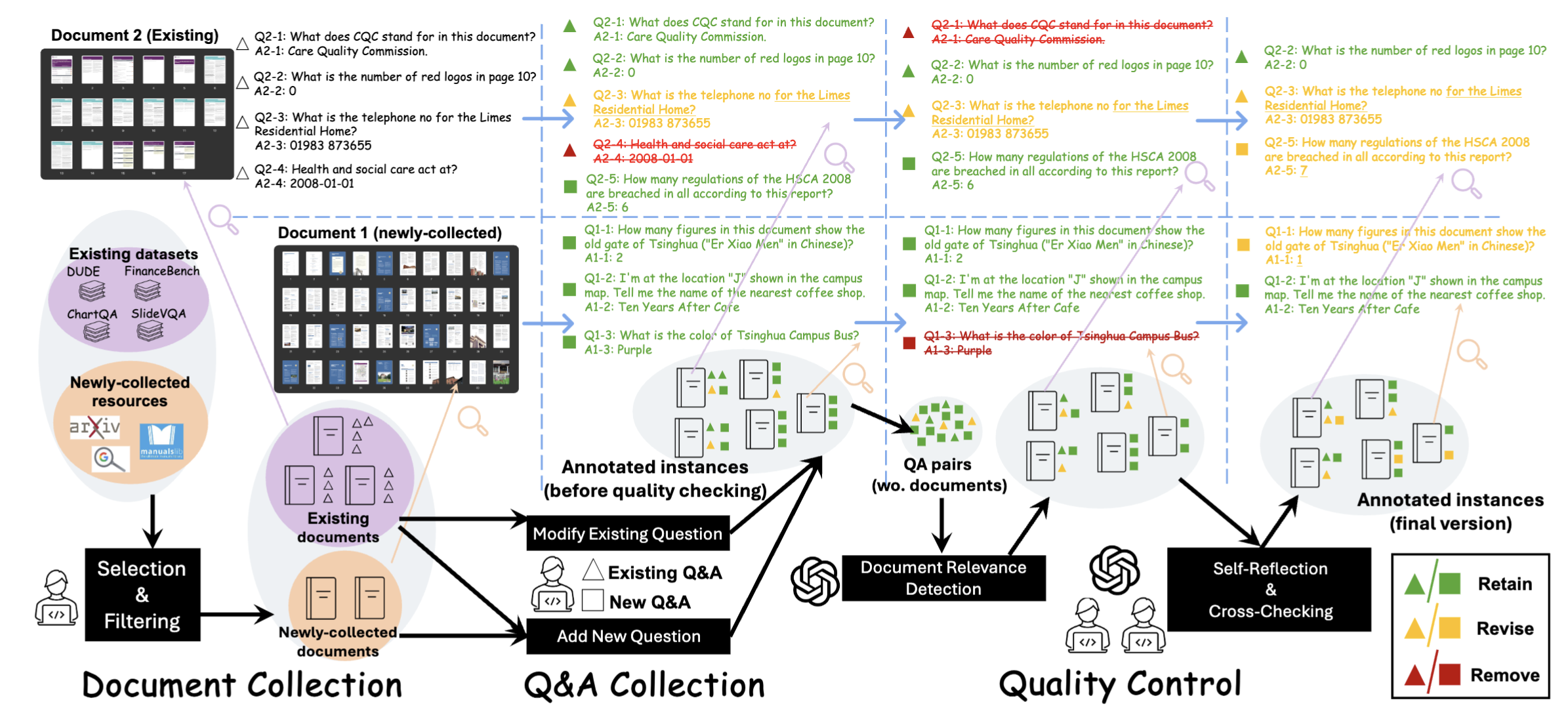
MMLongBench-Doc Evaluation
We conduct extensive experiments on MMLONGBENCH-DOC to evaluate the long-context DU abilities of 14 LVLMs (fed with PNG-formatted screenshots). For comparison, we also evaluate 10 LLMs (fed with OCR-parsed, TXT-formatted tokens). Our key findings are summarized as follows.
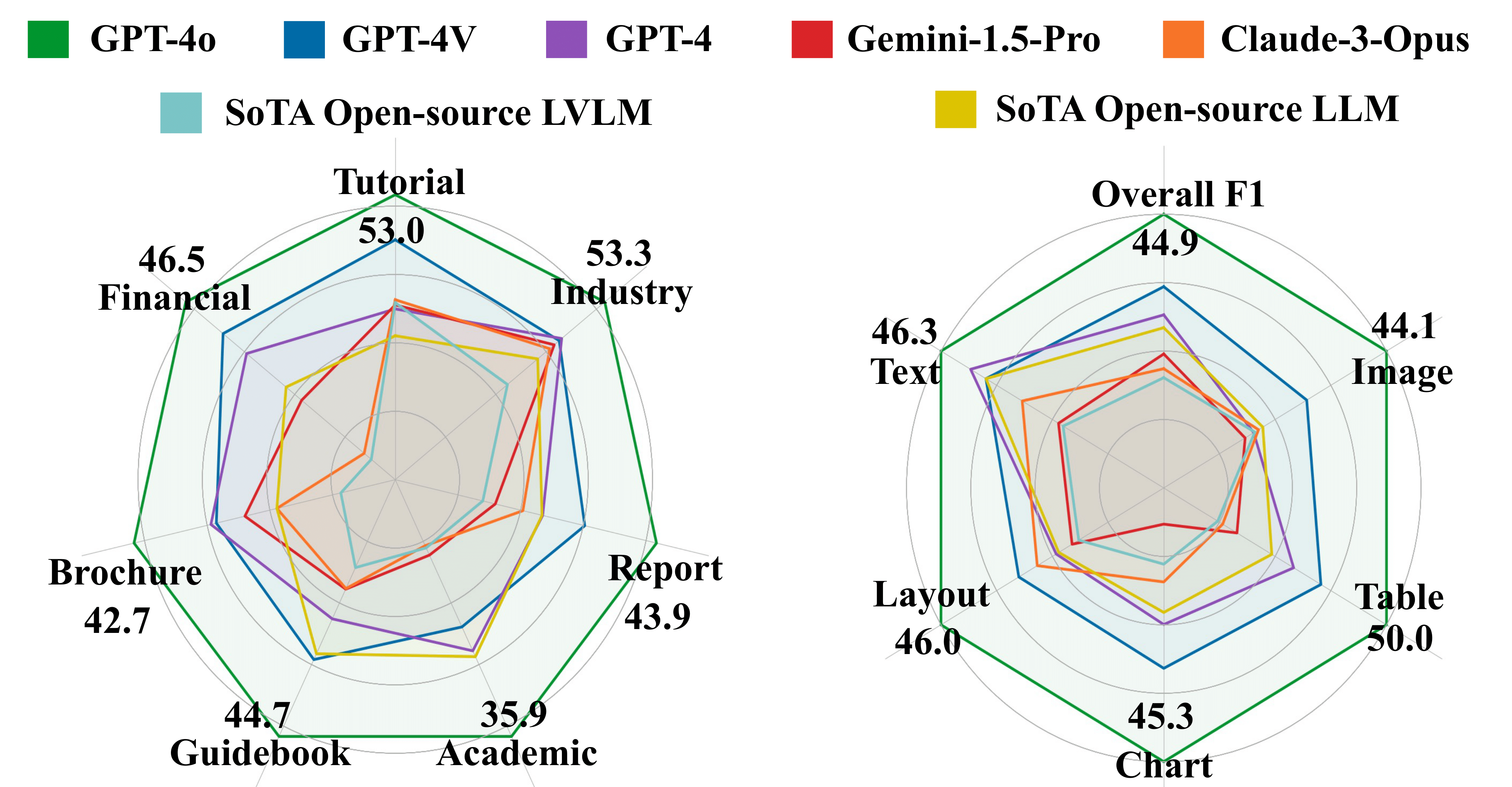
- Our benchmark poses significant challenges to current LVLMs. The best-performing LVLM, GPT-4o, achieves an overall F1 score of only 44.9%. while the second-best LVLM, GPT-4V, scores 30.5%. Among open-source evaluated LVLMs, only InternVL-Chat-v1.5 achieves more than 10% F1 score.
- 12 out of 14 LVLMs (except GPT-4o and GPT-4v) present inferior performance than their LLM counterparts, even though LLMs handle lossy, OCR-parsed texts. We speculate that the scarce related pre-training corpus (i.e., extremely multi-image or lengthy documents) hinders the long-context DU capabilities of LVLMs. We will leave related explorations for future work.
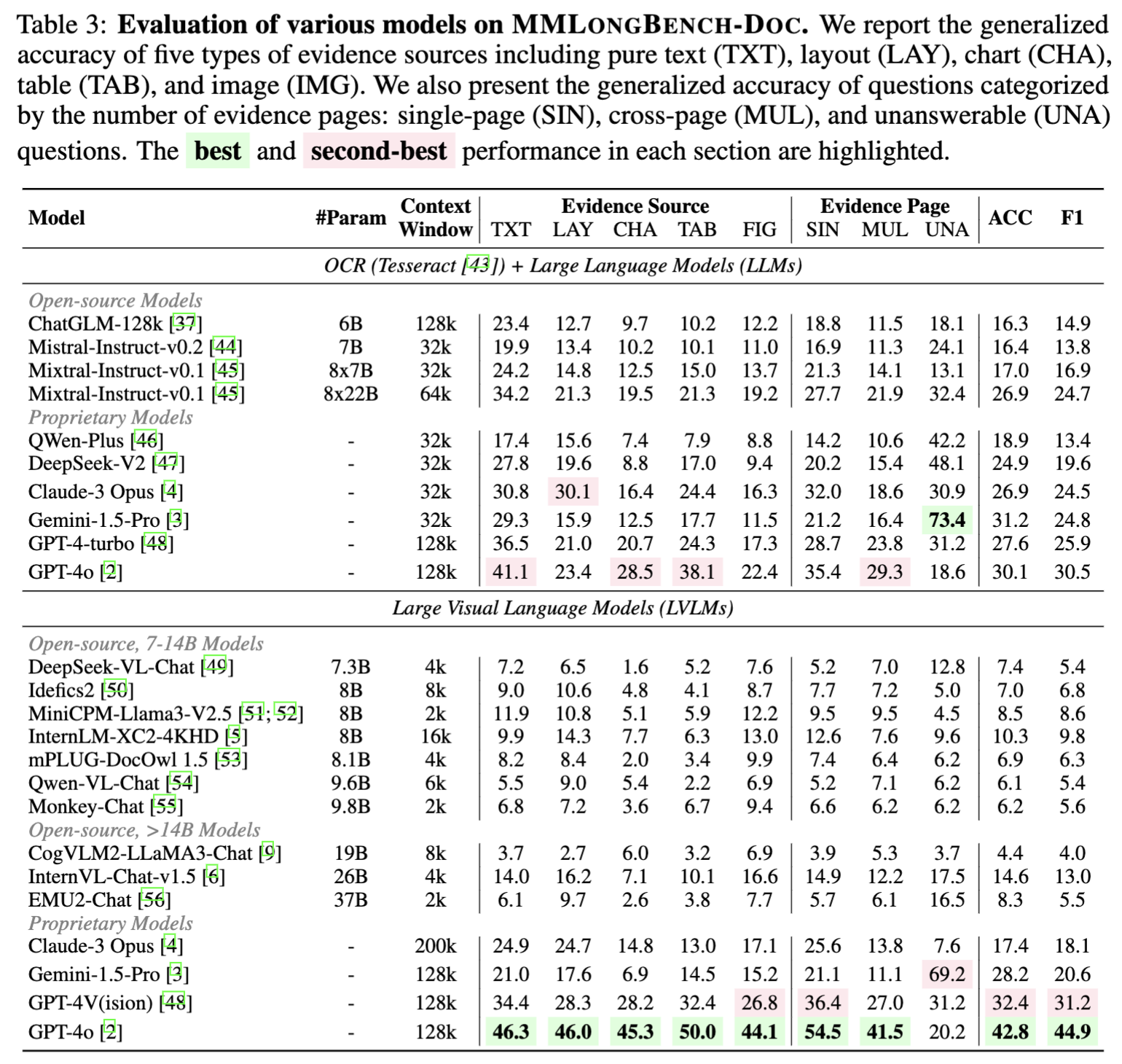
- Document Type: The performance on different documents varies. Generally speaking, all models demonstrate decent performance on industrial documents (more standardized formats and less non-textual information). But most models perform significantly worse in specialized domains such as academic papers and financial reports.
- Evidence Source: Only GPT-4o exhibits relatively balanced performance across different sources. LLMs demonstrate better or comparable performance to LVLMs on text-/table-related questions but worse performance on questions about other sources. This highlights the limitations of OCR when dealing with charts and images.
Case Study
Comparisons among responses from six models reveals that GPT-4o outperforms all other models by a significant margin in terms of perceiving visual information, reasoning over multiple pages, and generating richer responses.